人类要实现真正的具身智能,机器不仅要看懂世界,还要能重建世界。
忆生科技两项研究工作——多模态新基准研究All-Angles Bench与全局 3D 高斯场景维护LongSplat两项研究再获顶会认可。
近期,忆生科技联合合作伙伴的两项研究工作再获顶会认可。多模态新基准研究All-Angles Bench与全局 3D 高斯场景维护LongSplat双双入选将于新加坡举行的顶级人工智能学术会议 AAAI 2026,其中 LongSplat 入选口头报告(Oral)环节。
看懂世界
Seeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs
忆生科技联合多家知名高校与机构的研究者联合提出的All-Angles Bench,旨在全面评估MLLMs的多视图理解能力。它涵盖了90个真实场景下,超过2100组人工标注的多视图问答对。

论文地址:https://arxiv.org/abs/2504.15280
项目主页:https://danielchyeh.github.io/All-Angles-Bench/
如果说具身智能需要的是「带身体的大脑」,那 Seeing from Another Perspective 想回答的问题是:
在多视角场景里,今天的大模型到底有多「晕」?以及它们离「像人一样从不同视角理解同一世界」还有多远?
我们对27个领先的多模态大语言模型进行基准测试,其中包括Gemini-2.0-Flash、Claude-3.7-Sonnet和GPT-4o。

结果显示,多模态大语言模型与人类水平之间存在显著差距,并进一步发现模态大语言模型存在两种主要的缺陷模式:(1)在遮挡情况下跨视图对应能力较弱;(2)对粗略相机位姿的估计能力较差。
以上发现直指当下模型在「空间智能(Spatial Intelligence)」上的根本短板。
空间智能是人类理解世界最基本的能力之一——我们可以轻松在脑海中重建场景、在不同视角之间切换、推断物体的三维关系。但多模态大模型虽然在图像理解和语言能力上取得快速进展,却在这些空间能力上表现出明显不足:
无法稳定建立不同视角之间的结构一致性
缺乏对物体遮挡关系、相对深度与几何布局的可靠推理
难以形成“场景的心智模型”,因此无法像人类一样灵活地在视角之间转换
换句话说,当涉及空间理解时,今天的大模型依然更像是“在看图片”,而不是“在看世界”。
更多信息可查看AI领域知名媒体量子位对该工作的介绍:忆生科技与多所全球知名高校联合研究提出多模态新基准:考察多视图理解能力。
原文链接GPT-4o不敌Qwen,无一模型及格!UC伯克利/港大等联合团队提出多模态新基准:考察多视图理解能力
重建世界
LongSplat: Online Generalizable 3D Gaussian Splatting from Long Sequence Images

这是一个专为长序列图像设计的实时3D高斯重建框架。核心思想是在流式增量更新机制下,实现对3D高斯场的持续优化:每处理一帧新图像时,一方面融合当前帧提取的场景信息,另一方面压缩历史帧累积的冗余信息。 LongSplat 已确认入选口头报告(Oral)环节。
LongSplat 简介
LongSplat提出了一种面向长序列图像的在线3D高斯溅射重建框架,针对传统3DGS必须对每个场景进行分钟级至小时级优化、以及可泛化3DGS在高密度多视角下易产生高斯点冗余、漂浮伪影、内存与算力开销失控等问题,试图在实时性与重建质量之间取得新的平衡。
方法上,LongSplat引入流式增量更新机制:对每一帧输入同时执行在线融合(Online Integration)与自适应压缩(Adaptive Compression)。前者将当前帧预测的增量高斯与全局场景表示融合,持续精炼3D场;后者选择性删除历史视角中冗余高斯,控制高斯总量与内存占用,避免长序列重建过程中表示规模无界膨胀。
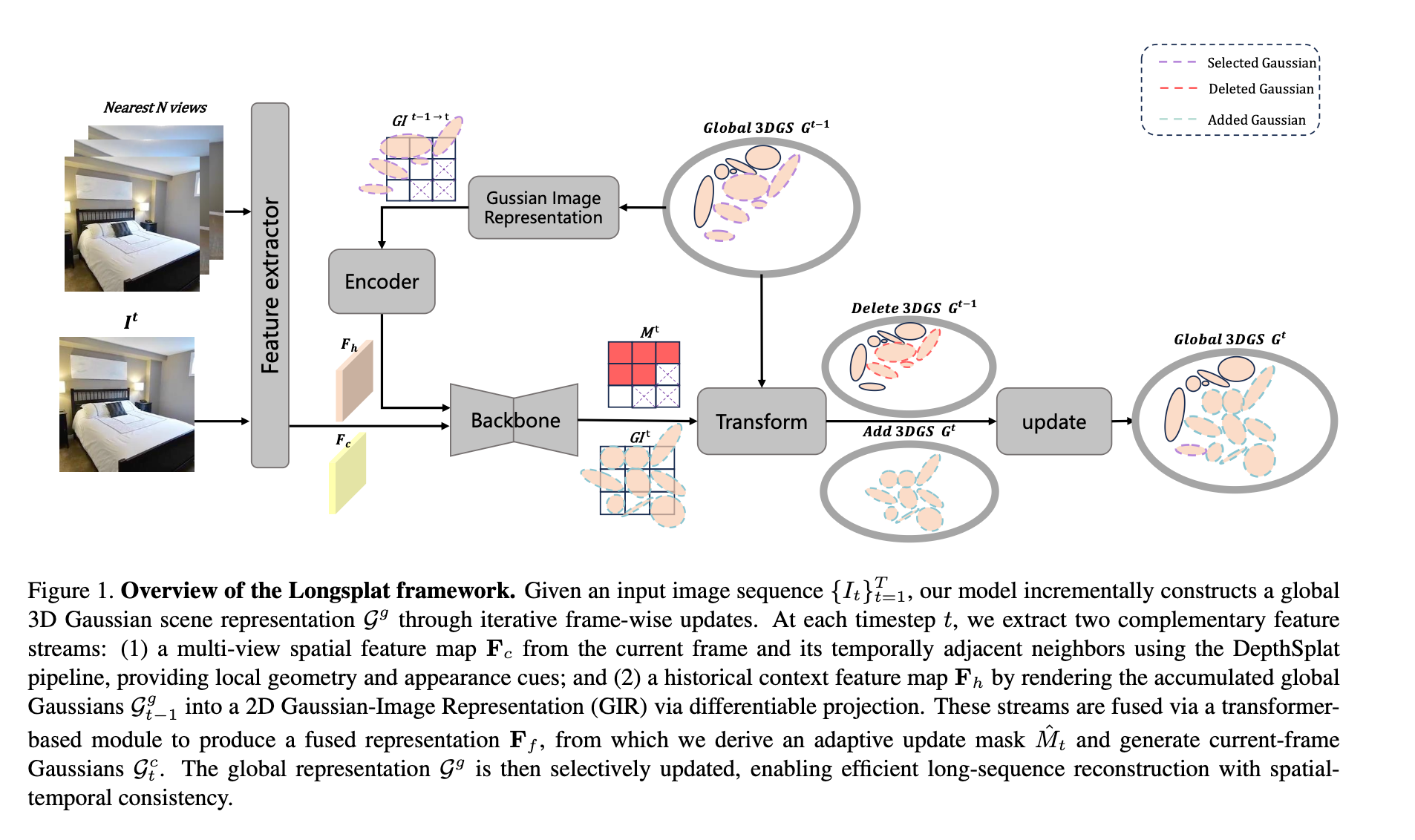
为高效连接3D表示与2D监督,作者提出Gaussian-Image Representation(GIR):将累积的3D高斯依当前相机位姿投影到2D平面,每个像素记录权重最高的高斯属性,实现像素与3D高斯的一一对应。GIR使跨帧信息在对齐的2D图像空间中完成融合,并支持在2D上进行卷积处理、误差回传与局部重投影,从而以较低开销更新全局3D场景。此外,LongSplat结合LightGaussian等高质量“教师”高斯场景,将其投射为GIR作为监督信号,仅依赖2D损失即可学习到紧凑且高保真的3D高斯表示。
在DL3DV等多视角重建基准上,LongSplat在保证实时渲染的前提下,相比逐像素预测类方法将全局高斯数量削减约44%,显著提升表示紧凑性。在120帧长序列下,其重建质量明显优于DepthSplat,PSNR提升约3.6 dB,在SSIM与LPIPS等指标上也更优;在中等长度序列(如50帧)上,完整模型与压缩变体在移除约43.8%高斯后仍保持接近的PSNR,展示了“高压缩率下近乎无损”的特性。同时,在主观视觉上,LongSplat有效抑制漂浮伪影,更好保留复杂几何与细节纹理。
此前的模型在「空间智能(Spatial Intelligence)」感知中存在明显痛点,它们无法区分已重建区域和新增区域,无法像人类一样准确找到不同视角中的重复区域,进而不断地进行冗余的重建,限制了其正确地感知空间信息。而LongSplat通过“增量更新 + GIR + 自适应压缩”,将复杂3D问题部分转化到2D图像域中高效求解,构建了一个适用于长序列在线重建的3DGS新范式,解决了当前模型的痛点。为机器人自主导航、AR/VR连续场景建模等实时三维感知任务提供了具有工程落地潜力的通用基础框架。
两篇工作分别对应世界模型链路上的两个问题:
我看到的,跨视角信息是否指向同一个世界?(多视角一致性与几何理解)
我能不能稳定、经济地在脑中/显存里搭起所观察到的场景?(3D 重建与表示)
未来,无论是家庭机器人、工业协作机器人场景,还是 AR/VR 的“世界数字孪生”场景,多视角理解 + 高效 3D 重建都是重要的基础能力。
一直以来,忆生科技坚定向着以视觉感知和运动控制为基础的世界模型迈进,以求真正将视觉感知能力转化为识别、预测、推理以及理解物理世界并与之互动的能力,为智能机器装上“大脑+小脑”。