
忆生科技(Transcengram)联合港大(HKU)以及腾讯的团队提出 CUPID(In-Cube Pixel Distribution)方法,首次将三维重建与位姿估计融合为一个端到端的生成任务。该方法能从单张图像同时输出物体的规范三维模型和精确的相机位姿,作者将这一创新命名为姿态锚定式三维重建(Pose-grounded 3D reconstruction)。
机器人与AR/VR 等具身智能场景里,系统不仅要“想象”看起来合理的三维物体,更要精确定位当前视角相对于物体的位置与朝向——这两项信息直接决定了机器人能否准确抓取、操作物体,以及用户能否自然地与虚拟内容交互。
然而,现有方法通常只能解决单一问题:要么估计相机位姿,要么做视角中心(view-centric)的三维重建,无法兼顾两者。即使有研究尝试"先生成、后估计"的两步法,也因生成内容的不确定性导致位姿估计不够稳定。
以往工作通常只解决其中一项:要么估计多视角姿态,要么做视角中心(view-centric)的三维重建,或仅做三维生成而不输出位姿信息,缺乏统一的框架。虽有工作尝试"先生成后估计"的多步骤方案,但生成内容的多样性往往导致姿态估计不稳定。
现在,港大(HKU)、忆生科技(Transcengram)以及腾讯的团队提出 CUPID(In-Cube Pixel Distribution)方法,首次将三维重建与位姿估计融合为一个端到端的生成任务。该方法能从单张图像同时输出物体的规范三维模型和精确的相机位姿,作者将这一创新命名为姿态锚定式三维重建(Pose-grounded 3D reconstruction)。

论文标题:CUPID:Pose-Grounded Generative 3D Reconstruction from a Single Image
论文地址:https://arxiv.org/abs/2510.20776
项目主页:https://cupid3d.github.io/
为什么重要?
马毅教授在其社交媒体上这样介绍该工作:“它展示了,基于学习到的3D物体的分布(视觉记忆),我们可以从单张(或多张)2D图像恢复物体完整的三维结构和纹理以及以物体或者观察者为中心的三维视角信息。这项工作将基于2D图像的3D重建与3D生成完美的结合在一起,为真正理解三维场景中物体之间以及与观察者之间的相互几何关系提供了必不可少的工具。在我二十年前写的第一本三维视觉的教材An Invitation to 3D Vision 中,我们曾揭示过,对于有对称结构的物体,从少量2D图像恢复如此完整的3D信息是可能的。而这项工作表明:只要能提前学到三维物体的整体分布(或者叫3D视觉记忆),那么对于一般的物体,从任意2D图像恢复一般物体的3D结构以及3D视角信息也是可行的。这样重建的3D模型,就不再只局限于让人看看而已。而是可以支持任何需要环境中物体/观察者之间空间关系信息的规划、推理、交互、操作任务。与我们的大脑观察环境中物体时所做的事情相似。”
方法一览:把“姿态”变成三维体素里的“UV 颜色”
核心想法:
CUPID将相机姿态估计转化为一个巧妙的"着色"问题——为三维体素的每个点标注其在输入图像上的投影坐标(u, v)。这就像给三维模型涂上一层"视角相关的UV颜色",随后通过经典的PnP算法从这些稠密的3D-2D对应关系中反推出相机的精确位姿。
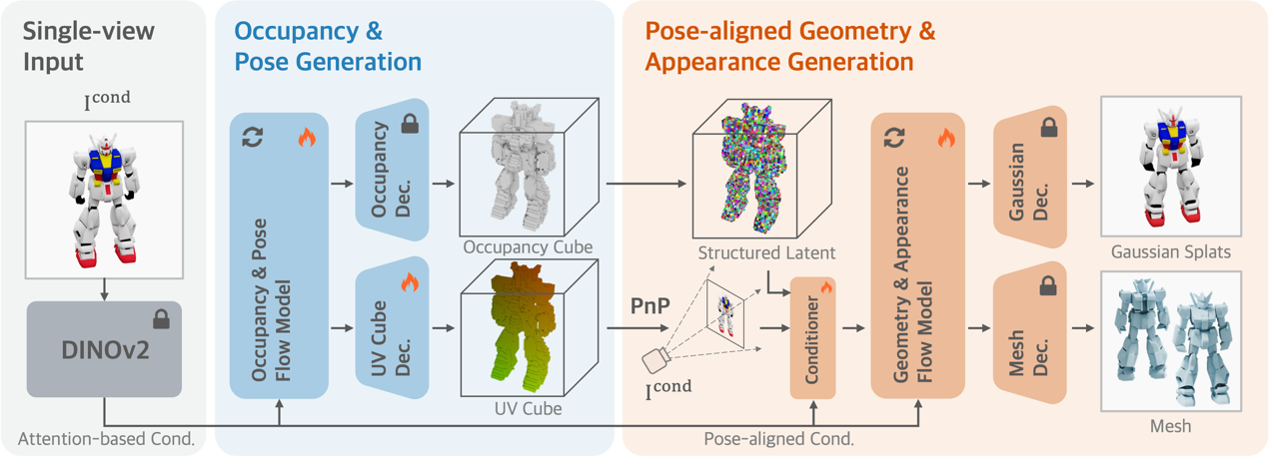
两阶段生成流程:
1. 粗阶段——联合生成形状与姿态:系统同时生成物体的占据体素(表示形状)和UV体素(表示每个点到图像的对应),并通过PnP算法直接解算相机位姿。
2. 细化阶段——姿态引导的高精度重建:利用已获得的姿态信息,将图像特征精准地反投影到三维空间,进一步生成高质量的几何和纹理细节,最终输出网格或高斯点云。这种"姿态条件细化"有效避免了颜色漂移,显著提升重建质量。
在技术实现上,CUPID采用Rectified Flow框架,通过条件流匹配(CFM)学习从噪声到真实数据的稳定生成路径,确保姿态与几何的精确控制。
与现有方法有何不同?
端到端的姿态感知生成:传统方法通常将三维生成和位姿估计分开处理——先生成模型,再事后对齐,不仅计算开销大,还容易出现匹配错误。CUPID从一开始就将位姿嵌入生成过程,确保重建结果与输入视角天然对齐,渲染一致性更强。
对象为中心(object-centric),而非视角为中心(view-centric):现有方法如LRM、LaRa等直接在相机视角坐标系下重建三维,导致同一物体在不同视角下会生成不同的表示。CUPID则在统一的物体规范坐标系中生成模型,输入图像仅用于确定观察位姿。这种设计让重建结果更加稳定可靠,便于后续的操作和推理任务。
结果
视觉质量与几何精度全面领先
在Toys4K和GSO两个标准3D物体数据集上,CUPID在输入视角渲染质量、几何精度和位姿估计三个维度均取得显著提升,超越了现有的主流三维重建与生成方法。
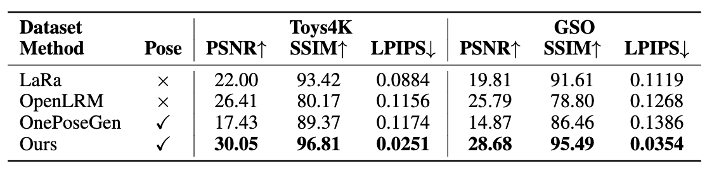
输入视角渲染质量:
CUPID在PSNR、SSIM和LPIPS等图像质量指标上全面超越LaRa和OpenLRM等前沿重建模型。例如,PSNR分别达到30.05和28.68,比现有方法提升超过3 dB。更重要的是,CUPID在保持高保真纹理的同时,还能输出精确的相机位姿(表中"Pose"列标记为✓),这是其他方法所不具备的。

单目几何重建精度:
在GSO数据集上,CUPID的Chamfer Distance和F-score指标表现优异,将OpenLRM的平均Chamfer Distance降低超过10%。值得注意的是,CUPID在中位数指标上已接近甚至超越VGGT等基于点图回归的方法——而后者仅能恢复可见表面的几何,无法生成完整的三维模型。
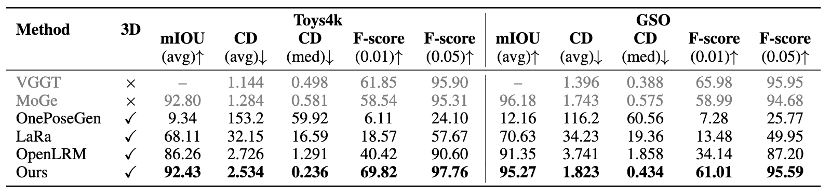
综合来看,CUPID相较主流方法在PSNR上提升超过3 dB,几何误差降低超过10%,位姿精度与专门的单目估计器持平,同时在视觉保真度上显著优于现有的3D生成基线。这验证了"姿态锚定式重建"范式的有效性。
多物体场景重建:从单个物体到完整场景
CUPID不仅能重建单个物体,还能扩展到复杂的多物体场景。具体流程如下:
首先,使用2D分割模型将场景分解为独立的物体组件;然后,对每个组件分别进行"遮挡感知"的三维重建,即使物体部分被遮挡也能恢复完整形状;最后,借助单目深度估计方法(如MoGe)提供的全局深度信息,将各个物体从其规范坐标系利用三维-三维相似变换精确对齐到统一的相机坐标系中,完成场景的组合式重建。
这种"分而治之"的策略让CUPID能够处理真实场景中的复杂布局,为机器人操作、AR场景理解等应用提供了完整的三维场景表示。

多视图输入:零样本扩展到多角度重建
虽然CUPID在训练时仅使用单视图监督,但在测试阶段也可以无缝扩展到多视图输入。借鉴2D图像生成领域MultiDiffusion的思路,CUPID将来自不同视角的生成轨迹在采样过程中进行平均融合,实现多视图条件的零样本(zero-shot)整合。
这意味着无需额外训练,模型就能利用多个角度的图像信息,进一步提升重建质量和姿态估计精度。下图展示了同时输入多张不同视角图像后的联合三维重建与姿态估计效果。

展望
当前方法的三点改进空间:
1. 对分割精度敏感: 方法依赖准确的物体掩码输入,边界分割误差会直接影响重建质量。
2. 光照与材质耦合: 当前模型可能将场景光照"烘焙"进物体纹理,未来需要更好地分离材质本身与环境光照的影响。
3. 输入位姿泛化能力: 由于训练数据多为居中构图,对于画面边缘或非中心位置的物体,重建效果仍有提升空间。
该方法还有不少的扩展空间。未来方向包括将方法扩展到动态物体重建场景,并进一步打通"已知姿态的三维生成"与"已知三维的姿态估计"两个方向,形成更完整的闭环系统,更好地服务于AR/VR内容创建和机器人智能操作等实际应用。