
该工作由加州大学伯克利分校、香港大学研究者共同完成。其中,作者之一Jingfeng Yang现为忆生科技实习生。Yi Ma为忆生科技创始人。
论文标题:Language-Image Alignment with Fixed Text Encoders
地址:https://arxiv.org/pdf/2506.04209
GitHub:https://jingfeng0705.github.io/LIFT/
多模态对齐模型近年来凭借对比学习范式在图像检索、文生图等任务中表现出色。然而,主流框架(如 CLIP)需要从零训练文本和图像编码器,导致计算成本高昂,尤其在处理长文本或大规模数据时更加明显。
近期,相关工作尝试将预训练的大语言模型(LLM)作为文本编码器融入多模态对齐框架,并在分类和检索任务上观察到性能提升。
然而,性能提升背后的机制尚不清晰,几个关键问题仍未得到系统解答:
能力提升的本质:LLM文本编码器的加入究竟增强了多模态模型的哪些具体能力?
数据特征的适配:在哪些类型的训练数据上,LLM文本编码器表现更优,原因为何?
关键组件的贡献:LLM文本编码器的哪些设计选择对跨模态对齐至关重要?
训练流程的简化:若使用LLM作为固定文本编码器,传统对比学习框架能否进一步优化?
来自UC伯克利和香港大学的研究团队在最新工作LIFT(Language-Image Alignment with Fixed Text Encoders)中,对上述问题进行了系统性解答。

论文链接:https://arxiv.org/pdf/2506.04209
项目代码:https://github.com/Jingfeng0705/LIFT
该方法采用极简训练范式——直接冻结预训练LLM作为文本编码器,仅优化图像编码器。
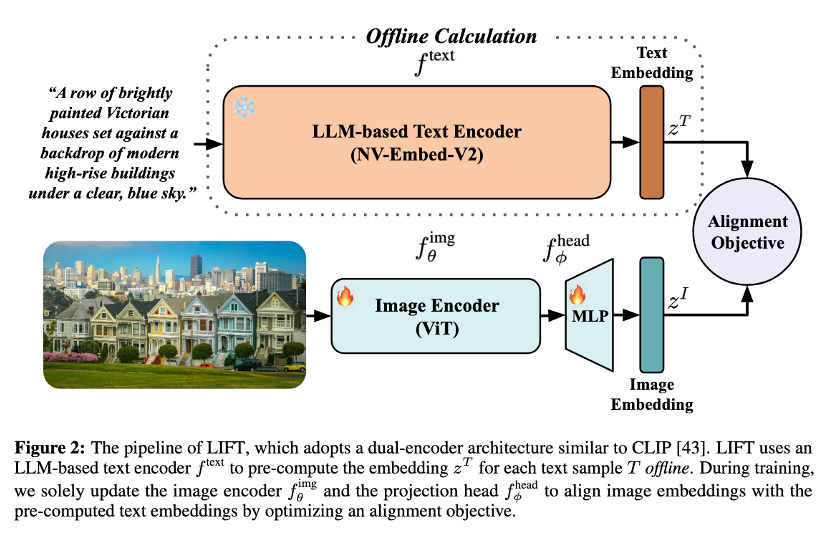
LIFT首次阐明了LLM文本嵌入驱动语言-视觉对齐的关键机制,并为未来高效多模态模型的设计提供了全新思路。
能力提升的本质 「组合语义」理解大幅提升
大量实验证明,CLIP及其变体缺乏「组合语义」理解(如词序、空间关系、物体-物体关系, 物体-属性关联等)。
学界普遍认为,对比预训练促使从零训练的编码器倾向于学习「捷径」,即丢弃与组合语义相关的特征。
在面向组合语义的SugarCrepe测试集上,LIFT相较CLIP在短文本训练场景下平均准确率提升6.8%,长文本训练场景下进一步提升至7.9%,在「添加属性」、「替换属性」与「替换关系」等子任务中优势尤为显著。
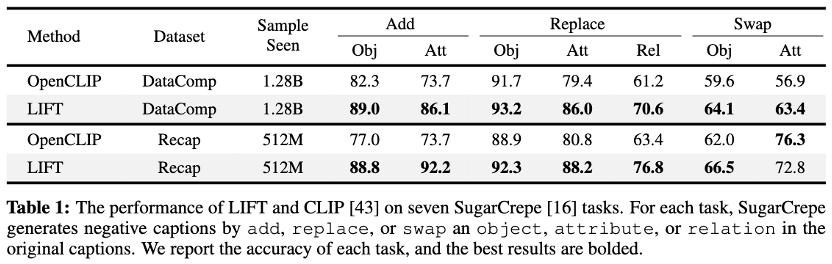
这表明,LLM的自回归训练能有效避免对比学习的组合语义盲区,更精准地建模物体间以及物体与其属性间的关联。
团队进一步以LIFT和CLIP作为图像编码器训练LLaVA式多模态大模型进行对比,以短文本训练的LIFT赢得6个LLaVA下游任务中的5项,而在长文本训练场景下全部取胜。
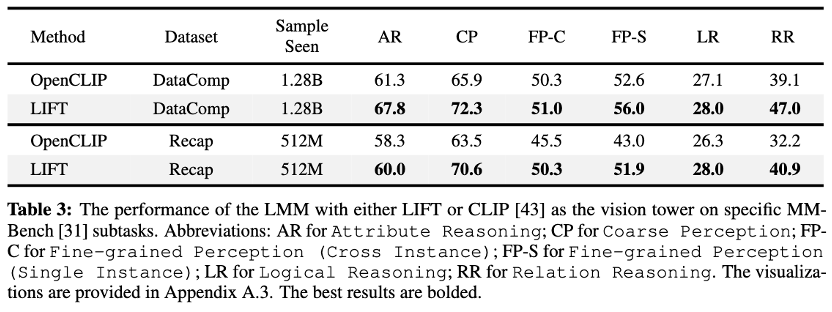
LIFT在MMBench的细粒度感知与关系推理子任务上取得最大增益,这表明LIFT的组合语义理解优势可无缝迁移到大型多模态模型,显著提升物体定位、属性识别及物理关系判断等视觉任务能力。
数据特征的适配 在合成长文本中优势显著
由多模态模型合成的长文本在语言-视觉对齐中正发挥日益重要的作用,因其能提供更丰富的图像细节信息。
现有研究已发现,LLM文本编码器在处理此类长文本时不仅效率更高,还能带来性能提升。

LIFT通过一系列实验再次证实这一现象,并进一步揭示了其背后的深层原因:预训练LLM文本编码器对合成长文本的句法相似性具有更强的鲁棒性。
团队发现,合成文本通常遵循固定句法模板,这会扭曲原始文本分布,并分散从零训练的文本编码器对核心语义的关注。
通过研究从Recap-DataComp-1B合成数据集中随机抽取的图像文本对,团队发现CLIP的文本编码器容易赋予句法相似但语义迥异的图像标题对高相似度。
相比之下,LIFT采用海量文本预训练的LLM文本编码器能有效抵抗句法干扰,更精准地聚焦语义内容,赋予这些生成文本对更合理的相似度评分。
关键组件的贡献 对比微调至关重要
在LLM文本编码器逐渐超越传统文本编码器的过程中,文本嵌入提取方式、对比微调等策略是最为关键的设计要素。为探究哪些设计真正有助于语言-视觉对齐,团队选取了五种7B规模的LLM作为LIFT的文本编码器进行对比实验。
结果显示,未经微调的原始LLM表现显著落后,在ImageNet-1K零样本分类任务中平均准确率下降22.8%,这表明LLM本身难以提供高质量的文本嵌入,对比微调对于语言-视觉对齐至关重要。要。
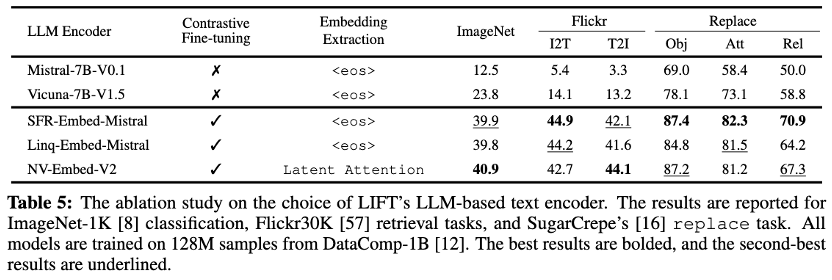 三种微调后的模型均取得良好且相近的表现,既验证了对比微调的有效性,也说明简单的<eos>隐状态已能有效表征文本,复杂的嵌入提取方法可能并非必要
三种微调后的模型均取得良好且相近的表现,既验证了对比微调的有效性,也说明简单的<eos>隐状态已能有效表征文本,复杂的嵌入提取方法可能并非必要
训练流程的简化 极简Cosine Similarity Loss
CLIP依赖基于余弦相似度的InfoNCE对比损失来防止模式坍缩,但其计算量和显存需求会随批次大小呈平方级增长,且严重依赖大批量负样本。
而预训练的LLM文本编码器解决了模式坍缩问题,因此团队尝试改用仅计算正向图像文本对的极简余弦相似度损失来实现对齐。
这种损失函数使FLOPs和显存需求降至线性复杂度,完全摆脱了对负样本和大批次的依赖。
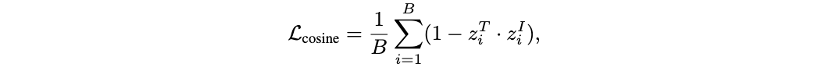
实验表明,在组合语义理解和LLaVA下游任务上,简化后的损失函数与InfoNCE表现相当;使用长文本训练时,该损失函数甚至在中英MMBench测试中显著领先。
然而,其在零样本分类与检索任务中准确率有所下降。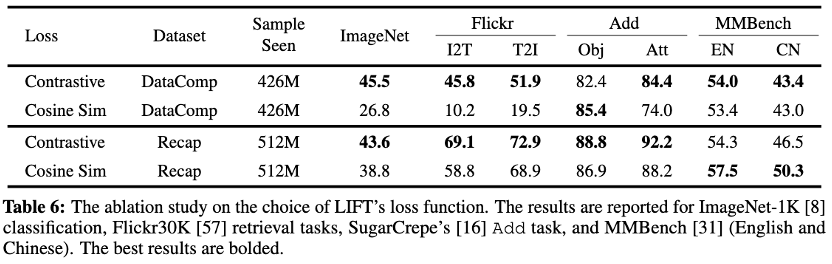
团队认为这一差距源于缺乏负样本导致表征区分度不足,证明对比损失函数在分类和检索任务中仍具有独特优势。
总结与后续工作
LIFT采用极简的训练范式,结合系统测试与消融实验,首次剖析了LLM文本嵌入驱动语言-视觉对齐的关键机制,归纳出四大核心发现:
相比从零训练的文本编码器, LLM文本编码器带来的多模态模型性能提升主要来自于更强的组合语义理解能力;
面对句法模板化、语义信息丰富的合成长文本,LLM编码器具备更强的鲁棒性与判别力;
在语言-视觉对齐中,对比微调对于LLM文本编码器至关重要,而复杂的嵌入提取方式并非必要,<eos>隐状态即可胜任;
在固定文本编码器后,用仅含正样本的极简线性余弦损失即可替代InfoNCE,对组合语义理解、LLaVA下游任务无损甚至有益。
未来,团队将把该简化范式与自监督等视觉表征学习策略结合,进一步细化并丰富语义联结。
此外,当前对齐仍主要停留在低阶统计层面,如何实现局部视觉特征与对应语义的深度耦合,将成为下一阶段的核心研究方向。
参考资料:
https://arxiv.org/pdf/2506.04209